КУРСОВАЯ РАБОТА
Аппроксимация функции методом наименьших квадратов
Введение
эмпирический mathcad аппроксимация
Целью курсовой работы является углубление знаний по информатике, развитие и закрепление навыков работы с табличным процессором Microsoft Excel и MathCAD. Применение их для решения задач с помощью ЭВМ из предметной области, связанной с исследованиями.
В каждом задании формулируются условия задачи, исходные данные, форма выдачи результатов, указываются основные математические зависимости для решения задачи Контрольный расчет позволяет убедиться в правильности работы программы.
Понятие аппроксимация представляет собой приближенное выражение каких-либо математических объектов (например, чисел или функций) через другие более простые, более удобные в использовании или просто более известные. В научных исследованиях аппроксимация применяется для описания, анализа, обобщения и дальнейшего использования эмпирических результатов.
Как известно, между величинами может существовать точная (функциональная) связь, когда одному значению аргумента соответствует одно определенное значение, и менее точная (корреляционная) связь, когда одному конкретному значению аргумента соответствует приближенное значение или некоторое множество значений функции, в той или иной степени близких друг к другу. При ведении научных исследований, обработке результатов наблюдения или эксперимента обычно приходиться сталкиваться со вторым вариантом. При изучении количественных зависимостей различных показателей, значения которых определяются эмпирически, как правило, имеется некоторая их вариабельность. Частично она задается неоднородностью самих изучаемых объектов неживой и, особенно, живой природы, частично обуславливается погрешностью наблюдения и количественной обработке материалов. Последнюю составляющую не всегда удается исключить полностью, можно лишь минимизировать ее тщательным выбором адекватного метода исследования и аккуратностью работы.
Специалисты в области автоматизации технологических процессов и производств имеют дело с большим объёмом экспериментальных данных, для обработки которых используется компьютер. Исходные данные и полученные результаты вычислений могут быть представлены в табличной форме, используя табличные процессоры (электронные таблицы) и, в частности, Excel. Курсовая работа по информатике позволяет студенту закрепить и развить навыки работы с помощью базовых компьютерных технологий при решении задач в сфере профессиональной деятельности.- система компьютерной алгебры из класса систем автоматизированного проектирования, ориентированная на подготовку интерактивных документов с вычислениями и визуальным сопровождением, отличается легкостью использования и применения для коллективной работы.
1. Общие сведения
Очень часто, особенно при анализе эмпирических данных возникает необходимость найти в явном виде функциональную зависимость между величинами x и у , которые получены в результате измерений.
При аналитическом исследовании взаимосвязи между двумя величинами x и y производят ряд наблюдений и в результате получается таблица значений:
xx 1 x 1 x i X n уy 1 y 1 y i Y n
Эта таблица обычно получается как итог каких-либо экспериментов, в которых x, (независимая величина) задается экспериментатором, а у, получается в результате опыта. Поэтому эти значения у, будем называть эмпирическими или опытными значениями.
Между величинами x и y существует функциональная зависимость, но ее аналитический вид обычно неизвестен, поэтому возникает практически важная задача - найти эмпирическую формулу
y = f(x; a1, a2,…, am), (1)
(где a 1 , a 2 ,…, a m - параметры), значения которой при x = x, возможно мало отличались бы от опытных значений у, (i = 1,2,…, п) .
Обычно указывают класс функций (например, множество линейных, степенных, показательных и т.п.) из которого выбирается функция f (x) , и далее определяются наилучшие значения параметров.
Если в эмпирическую формулу (1) подставить исходные x, то получим теоретические значения
Y T i = f (x i ; a1, a2……a m ) , где i = 1,2,…, n .
Разности y i T - у i , называются отклонениями и представляют собой расстояния по вертикали от точек M i до графика эмпирической функции.
Согласно методу наименьших квадратов наилучшими коэффициентами a 1 , a 2 ,…, a m считаются те, для которых сумма квадратов отклонений найденной эмпирической функции от заданных значений функции
будет минимальной.
Поясним геометрический смысл метода наименьших квадратов.
Каждая пара чисел (x i , y i ) из исходной таблицы определяет точку M i на плоскости XOY. Используя формулу (1) при различных значениях коэффициентов a 1 , a 2 ,…, a m можно построить ряд кривых, которые являются графиками функции (1). Задача состоит в определении коэффициентов a 1 , a 2 ,…, a m таким образом, чтобы сумма квадратов расстояний по вертикали от точек M i (x i , y i ) до графика функции (1) была наименьшей (рис. 1).
Построение эмпирической формулы состоит из двух этапов: выяснение общего вида этой формулы и определение ее наилучших параметров.
Если неизвестен характер зависимости между данными величинами x и y , то вид эмпирической зависимости является произвольным. Предпочтение отдается простым формулам, обладающим хорошей точностью. Удачный выбор эмпирической формулы в значительной мере зависит от знаний исследователя в предметной области, используя которые он может указать класс функций из теоретических соображений. Большое значение имеет изображение полученных данных в декартовых или в специальных системах координат (полулогарифмической, логарифмической и т.д.). По положению точек можно примерно угадать общий вид зависимости путем установления сходства между построенным графиком и образцами известных кривых.
Определение наилучших коэффициентов a 1 , a 2,…, a m входящих в эмпирическую формулу производят хорошо известным аналитическими методами.
Для того, чтобы найти набор коэффициентовa a 1 , a 2 …..a m , которые доставляют минимум функции S, определяемой формулой (2), используем необходимое условие экстремума функции нескольких переменных - равенство нулю частных производных.
В результате получим нормальную систему для определения коэффициентов a i (i = 1,2,…, m) :
Таким образом, нахождение коэффициентов a i сводится к решению системы (3). Эта система упрощается, если эмпирическая формула (1) линейна относительно параметров a i , тогда система (3) - будет линейной.
1.1 Линейная зависимость
Конкретный вид системы (3) зависит от того, из какого класса эмпирических формул мы ищем зависимость (1). В случае линейной зависимости y = a 1 + a 2 x система (3) примет вид:
Эта линейная система может быть решена любым известным методом (методом Гаусса, простых итераций, формулами Крамера).
1.2 Квадратичная зависимость
В случае квадратичной зависимости y = a 1 + a 2 x + a 3x2 система (3) примет вид:
1.3 Экспоненциальная зависимость
В ряде случаев в качестве эмпирической формулы берут функцию в которую неопределенные коэффициенты входят нелинейно. При этом иногда задачу удается линеаризовать т.е. свести к линейной. К числу таких зависимостей относится экспоненциальная зависимость
y = a 1 * e a2x (6)
где a1 иa2, неопределенные коффициенты.
Линеаризация достигается путем логарифмирования равенства (6), после чего получаем соотношение
ln y = ln a1 + a2x(7)
Обозначим ln у и ln a x соответственно через t и c , тогда зависимость (6) может быть записана в виде t = a 1 + a 2 х , что позволяет применить формулы (4) с заменой a 1 на c и у i на t i
1.4 Элементы теории корреляции
График восстановленной функциональной зависимости у(х) по результатам измерений (хi , у i ), i = 1,2, K , n называется кривой регрессии. Для проверки согласия построенной кривой регрессии с результатами эксперимента обычно вводят следующие числовые характеристики: коэффициент корреляции (линейная зависимость), корреляционное отношение и коэффициент детерминированности. При этом результаты обычно группируют и представляют в форме корреляционной таблицы. В каждой клетке этой таблицы приводятся численности n iJ - тех пар (х, у) , компоненты которых попадают в соответствующие интервалы группировки по каждой переменной. Предполагая длины интервалов группировки (по каждой переменной) равными между собой, выбирают центры хi (соответственно у i ) этих интервалов и числа n iJ - в качестве основы для расчетов.
Коэффициент корреляции является мерой линейной связи между зависимыми случайными величинами: он показывает, насколько хорошо в среднем может быть представлена одна из величин в виде линейной функции от другой.
Коэффициент корреляции вычисляется по формуле:
где, и - среднее арифметическое значение соответственно х и у .
Коэффициент корреляции между случайными величинами по абсолютной величине не превосходит 1. Чем ближе |р| к 1, тем теснее линейная связь между х и у.
В случае нелинейной корреляционной связи условные средние значения располагаются около кривой линии. В этом случае в качестве характеристики силы связи рекомендуется использовать корреляционное отношение, интерпретация которого не зависит от вида исследуемой зависимости.
Корреляционное отношение вычисляется по формуле:
где n i = , n f = , а числитель характеризует рассеяние условных средних у, около безусловного среднего y .
Всегда. Равенство = 0 соответствует некоррелированным случайным величинам; = 1 тогда и только тогда, когда имеется точная функциональная связь междуy и x. В случае линейной зависимости y от x корреляционное отношение совпадает с квадратом коэффициента корреляции. Величина - ? 2 используется в качестве индикатора отклонения регрессии от линейной.
Корреляционное отношение является мерой корреляционной связи y с x в какой угодно форме, но не может дать представления о степени приближенности эмпирических данных к специальной форме. Чтобы выяснить насколько точно построенная кривая отражает эмпирические данные вводится еще одна характеристика - коэффициент детерминированности.
Для его описания рассмотрим следующие величины. - полная сумма квадратов, где среднее значение.
Можно доказать следующее равенство
Первое слагаемое равно Sост = и называется остаточной суммой квадратов. Оно характеризует отклонение экспериментальных от теоритических.
Второе слагаемое равно Sрегр = 2 и называется регрессионной суммой квадратов и оно характеризует разброс данных.
Очевидно, что справедливо следующее равенство Sполн = Sост + Sрегр.
Коэффициент детерминированности определяется по формуле:
Чем меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем больше значение коэффициента детерминированности r 2 , который показывает, насколько хорошо уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязи между переменными. Если он равен 1, то имеет место полная корреляция с моделью, т.е. нет различия между фактическим и оценочным значениями y. В противоположном случае, если коэффициент детерминированности равен 0, то уравнение регрессии неудачно для предсказания значений y
Коэффициент детерминированности всегда не превосходит корреляционное отношение. В случае когда выполняется равенство r 2 = то можно считать, что построенная эмпирическая формула наиболее точно отражает эмпирические данные.
2. Постановка задачи
1. Используя метод наименьших квадратов функцию, заданную таблично, аппроксимировать
а) многочленом первой степени;
б) многочленом второй степени;
в) экспоненциальной зависимостью.
Для каждой зависимости вычислить коэффициент детерминированности.
Вычислить коэффициент корреляции (только в случае а).
Для каждой зависимости построить линию тренда.
Используя функцию ЛИНЕЙН вычислить числовые характеристики зависимости от.
Сравнить свои вычисления с результатами, полученными при помощи функции ЛИНЕЙН.
Сделать вывод, какая из полученных формул наилучшим образом аппроксимирует функцию.
Написать программу на одном из языков программирования и сравнить результаты счета с полученными выше.
3. Исходные данные
Функция задана рисунком 1.
4. Расчет аппроксимаций в табличном процессоре Excel
Для проведения расчетов целесообразно воспользоваться табличным процессором Microsoft Excel. И данные расположить как показано на рисунке 2.
Для этого заносим:
·в ячейки A6:A30 заносим значения xi.
·в ячейки B6:B30 заносим значения уi.
·в ячейку C6 вводим формулу =А6^2.
·в ячейки C7:C30 эта формула копируется.
·в ячейку D6 вводим формулу =А6*В6.
·в ячейки D7:D30 эта формула копируется.
·в ячейку F6 вводим формулу =А6^4.
·в ячейки F7:F30 эта формула копируется.
·в ячейку G6 вводим формулу =А6^2*В6.
·в ячейки G7:G30 эта формула копируется.
·в ячейку H6 вводим формулу =LN(B6).
·в ячейки H7:H30 эта формула копируется.
·в ячейку I6 вводим формулу =A6*LN(B6).
·в ячейки I7:I30 эта формула копируется. Последующие шаги делаем с помощью автосуммирования
·в ячейку А33 вводим формулу =СУММ (А6:А30).
·в ячейку B33 вводим формулу =СУММ (В6:В30).
·в ячейку C33 вводим формулу =СУММ (С6:С30).
·в ячейку D33 вводим формулу =СУММ (D6:D30).
·в ячейку E33 вводим формулу =СУММ (E6:E30).
·в ячейку F33 вводим формулу =СУММ (F6:F30).
·в ячейку G33 вводим формулу =СУММ (G6:G30).
·в ячейку H33 вводим формулу =СУММ (H6:H30).
·в ячейку I33 вводим формулу =СУММ (I6:I30).
Аппроксимируем функцию y = f (x) линейной функцией y = a 1 + a 2x. Для определения коэффициентов a1 и a2 воспользуемся системой (4). Используя итоговые суммы таблицы 2, расположенные в ячейках A33, B33, C33 и D33, запишем систему (4) в виде
решив которую, получим a1 = -24,7164 и a2 = 11,63183
Таким образом, линейная аппроксимация имеет вид y= -24,7164 + 11,63183х (12)
Решение системы (11) проводили, пользуясь средствами Microsoft Excel. Результаты представлены на рисунке 3:
В таблице в ячейках A38:B39 записана формула {=МОБР (A35:B36)}. В ячейках E38:E39 записана формула {=МУМНОЖ (A38:B39, C35:C36)}.
Далее аппроксимируем функцию y = f (x) квадратичной функцией y = a 1 + a 2 x + a 3 x 2. Для определения коэффициентов a1, a2 и a3 воспользуемся системой (5). Используя итоговые суммы таблицы 2, расположенные в ячейках A33, B33, C33, D33, E33, F33 и G33 запишем систему (5) в виде:
Решив которую, получим a1 = 1,580946, a2 = -0,60819 и a3 = 0,954171 (14)
Таким образом, квадратичная аппроксимация имеет вид:
у = 1,580946 -0,60819х +0,954171 х 2
Решение системы (13) проводили, пользуясь средствами Microsoft Excel. Результаты представлены на рисунке 4.
В таблице в ячейках A46:C48 записана формула {=МОБР (A41:C43)}. В ячейках F46:F48 записана формула {=МУМНОЖ (A41:C43, D46:D48)}.
Теперь аппроксимируем функцию y = f (х) экспоненциальной функцией y = a 1 e a2x . Для определения коэффициентов a 1 и a 2 прологарифмируем значения y i и используя итоговые суммы таблицы 2, расположенные в ячейках A26, C26, H26 и I26 получим систему:
где с = ln(a 1 ).
Решив систему (10) найдем с = 0,506435, a2 = 0.409819.
После потенцирования получим a1 = 1,659365.
Таким образом, экспоненциальная аппроксимация имеет вид y = 1,659365*e 0,4098194x
Решение системы (15) проводили, пользуясь средствами Microsoft Excel. Результаты представлены на рисунке 5.
В таблице в ячейках A55:B56 записана формула {=МОБР (A51:B52)}. В ячейках E54:E56 записана формула {=МУМНОЖ (A51:B52, С51:С52)}. В ячейке E56 записана формула =EXP(E54).
Вычислим среднее арифметическое x и у по формулам:
Результаты расчета x и y средствами Microsoft Excel представлены на рисунке 6.
В ячейке B58 записана формула =A33/25. В ячейке B59 записана формула =B33/25.
Таблица 2
Поясним как таблица на рисунке 7 составляется.
Ячейки A6:A33 и B6:B33 уже заполнены (см. рис. 2).
·в ячейку J6 вводим формулу =(A6-$B$58)*(B6-$B$59).
·в ячейки J7:J30 эта формула копируется.
·в ячейку K6 вводим формулу =(А6-$В$58)^2.
·в ячейки K7:K30 эта формула копируется.
·в ячейку L6 вводим формулу =(В1-$В$59)^2.
·в ячейки L7:L30 эта формула копируется.
·в ячейку M6 вводим формулу =($Е$38+$Е$39*А6-В6)^2.
·в ячейки M7:M30 эта формула копируется.
·в ячейку N6 вводим формулу =($F$46 +$F$47*A6 +$F$48*A6 Л6-В6)^2.
·в ячейки N7:N30 эта формула копируется.
·в ячейку O6 вводим формулу =($Е$56*ЕХР ($Е$55*А6) - В6)^2.
·в ячейки O7:O30 эта формула копируется.
Последующие шаги делаем с помощью автосуммирования.
·в ячейку J33 вводим формулу =CYMM (J6:J30).
·в ячейку K33 вводим формулу =СУММ (К6:К30).
·в ячейку L33 вводим формулу =CYMM (L6:L30).
·в ячейку M33 вводим формулу =СУММ (М6:М30).
·в ячейку N33 вводим формулу =СУММ (N6:N30).
·в ячейку O33 вводим формулу =СУММ (06:030).
Теперь проведем расчеты коэффициента корреляции по формуле (8) (только для линейной аппроксимации) и коэффициента детерминированности по формуле (10). Результаты расчетов средствами Microsoft Ехcеl представлены на рисунке 7.
В таблице 8 в ячейке B61 записана формула =J33/(K33*L33^(1/2). В ячейке B62 записана формула =1 - M33/L33. В ячейке B63 записана формула =1 - N33/L33. В ячейке B64 записана формула =1 - O33/L33.
Анализ результатов расчетов показывает, что квадратичная аппроксимация наилучшим образом описывает экспериментальные данные.
4.1 Построение графиков в Excel
Выделим ячейки A1:A25, после этого обратимся к мастеру диаграмм. Выберем точечный график. После того как диаграмма будет построена, щелкнем правой кнопкой мышки на линии графика и выберем добавить линию тренда (соответственно линейную, экспоненциальную, степенную и полиномиальную второй степени).
График линейной аппроксимации
График квадратичной аппроксимации
График экспоненциальной аппроксимации.
5. Аппроксимация функции с помощью MathCAD
Аппроксимация данных с учетом их статистических параметров относится к задачам регрессии. Они обычно возникают при обработке экспериментальных данных, полученных в результате измерений процессов или физических явлений, статистических по своей природе (как, например, измерения в радиометрии и ядерной геофизике), или на высоком уровне помех (шумов). Задачей регрессионного анализа является подбор математических формул, наилучшим образом описывающих экспериментальные данные.
.1 Линейная регрессия
Линейная регрессия в системе Mathcad выполняется по векторам аргумента Х и отсчетов Y функциями:
intercept (x, y) - вычисляет параметр а 1 , смещение линии регрессии по вертикали (см. рис.)
slope (x, y) - вычисляет параметр a 2 , угловой коэффициент линии регрессии (см. рис.)
y(x) = a1+a2*x
Функция corr (у, y(x)) вычисляет коэффициент корреляции Пирсона. Чем он ближе к 1, тем точнее обрабатываемые данные соответствуют линейной зависимости (см. рис.)
.2 Полиноминальная регрессия
Одномерная полиномиальная регрессия с произвольной степенью n полинома и с произвольными координатами отсчетов в Mathcad выполняется функциями:
regress (х, у, n) - вычисляет вектор S, в составе которого находятся коэффициенты ai полинома n -й степени;
Значения коэффициентов ai могут быть извлечены из вектора S функцией submatrix (S, 3, length(S) - 1, 0, 0).
Полученные значения коэффициентов используем в уравнении регрессии
y(x) = a1+a2*x+a3*x 2 (см. рис.)
.3 Нелинейная регрессия
Для простых типовых формул аппроксимации предусмотрен ряд функций нелинейной регрессии, в которых параметры функций подбираются программой Mathcad.
К их числу относится функция expfit (x, y, s), которая возвращает вектор, содержащий коэффициенты a1, a2 и a3 экспоненциальной функции
y(x) = a1 ^exp (a2 x) + a3. В вектор S вводятся начальные значения коэффициентов a1, a2 и a3 первого приближения.
Заключение
Анализ результатов расчетов показывает, что линейная аппроксимация наилучшим образом описывает экспериментальные данные.
Результаты полученные с помощью программы MathCAD полностью совпадают со значениями полученными с помощью Excel. Это говорит о верности вычислений.
Список используемой литературы
- Информатика: Учебник / Под ред. проф. Н.В. Макаровой. М.: Финансы и статистика 2007
- Информатика: Практикум по технологии работы на компьютере / Под. Ред. проф. Н.В. Макаровой. М Финансы и статистика, 2011.
- Н.С. Пискунов. Дифференциальное и интегральное исчисление, 2010.
- Информатика, Аппроксимация методом наименьших квадратов, методические указания, Санкт-Петербург, 2009.
Репетиторство
Нужна помощь по изучению какой-либы темы?
Наши специалисты проконсультируют или окажут репетиторские услуги по интересующей вас тематике.
Отправь заявку
с указанием темы прямо сейчас, чтобы узнать о возможности получения консультации.
Одним из методов изучения стохастических связей между признаками является регрессионный анализ .
Регрессионный анализ представляет собой вывод уравнения регрессии, с помощью которого находится средняя величина случайной переменной (признака-результата), если величина другой (или других) переменных (признаков-факторов) известна. Он включает следующие этапы:
- выбор формы связи (вида аналитического уравнения регрессии);
- оценку параметров уравнения;
- оценку качества аналитического уравнения регрессии.
В случае линейной парной связи уравнение регрессии примет вид: y i =a+b·x i +u i . Параметры данного уравнения а и b оцениваются по данным статистического наблюдения x и y . Результатом такой оценки является уравнение: , где , - оценки параметров a и b , - значение результативного признака (переменной), полученное по уравнению регрессии (расчетное значение).
Наиболее часто для оценки параметров используют метод наименьших квадратов (МНК).
Метод наименьших квадратов дает наилучшие (состоятельные, эффективные и несмещенные) оценки параметров уравнения регрессии. Но только в том случае, если выполняются определенные предпосылки относительно случайного члена (u) и независимой переменной (x) (см. предпосылки МНК).
Задача оценивания параметров линейного парного уравнения методом наименьших квадратов
состоит в следующем: получить такие оценки параметров , , при которых сумма квадратов отклонений фактических значений результативного признака - y i от расчетных значений – минимальна.
Формально критерий МНК
можно записать так:  .
.
Классификация методов наименьших квадратов
- Метод наименьших квадратов.
- Метод максимального правдоподобия (для нормальной классической линейной модели регрессии постулируется нормальность регрессионных остатков).
- Обобщенный метод наименьших квадратов ОМНК применяется в случае автокорреляции ошибок и в случае гетероскедастичности.
- Метод взвешенных наименьших квадратов (частный случай ОМНК с гетероскедастичными остатками).
Проиллюстрируем суть классического метода наименьших квадратов графически
. Для этого построим точечный график по данным наблюдений (x i , y i , i=1;n) в прямоугольной системе координат (такой точечный график называют корреляционным полем). Попытаемся подобрать прямую линию, которая ближе всего расположена к точкам корреляционного поля. Согласно методу наименьших квадратов линия выбирается так, чтобы сумма квадратов расстояний по вертикали между точками корреляционного поля и этой линией была бы минимальной.

Математическая запись данной задачи:  .
.
Значения y i и x i =1...n нам известны, это данные наблюдений. В функции S они представляют собой константы. Переменными в данной функции являются искомые оценки параметров - , . Чтобы найти минимум функции 2-ух переменных необходимо вычислить частные производные данной функции по каждому из параметров и приравнять их нулю, т.е. 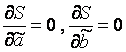 .
.
В результате получим систему из 2-ух нормальных линейных уравнений: 
Решая данную систему, найдем искомые оценки параметров:

Правильность расчета параметров уравнения регрессии может быть проверена сравнением сумм (возможно некоторое расхождение из-за округления расчетов).
Для расчета оценок параметров , можно построить таблицу 1.
Знак коэффициента регрессии b указывает направление связи (если b >0, связь прямая, если b <0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Формально значение параметра а – среднее значение y при х равном нулю. Если признак-фактор не имеет и не может иметь нулевого значения, то вышеуказанная трактовка параметра а не имеет смысла.
Оценка тесноты связи между признаками
осуществляется с помощью коэффициента линейной парной корреляции - r x,y .
Он может быть рассчитан по формуле:  . Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:
. Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:  .
.
Область допустимых значений линейного коэффициента парной корреляции от –1 до +1. Знак коэффициента корреляции указывает направление связи. Если r x, y >0, то связь прямая; если r x, y <0, то связь обратная.
Если данный коэффициент по модулю близок к единице, то связь между признаками может быть интерпретирована как довольно тесная линейная. Если его модуль равен единице ê r x , y ê =1, то связь между признаками функциональная линейная.
Если признаки х и y линейно независимы, то r x,y близок к 0.
Для расчета r x,y можно использовать также таблицу 1.
Для оценки качества полученного уравнения регрессии рассчитывают теоретический коэффициент детерминации – R 2 yx:
 ,
,
где d 2 – объясненная уравнением регрессии дисперсия y ;
e 2 - остаточная (необъясненная уравнением регрессии) дисперсия y ;
s 2 y - общая (полная) дисперсия y .
Коэффициент детерминации характеризует долю вариации (дисперсии) результативного признака y , объясняемую регрессией (а, следовательно, и фактором х), в общей вариации (дисперсии) y . Коэффициент детерминации R 2 yx принимает значения от 0 до 1. Соответственно величина 1-R 2 yx характеризует долю дисперсии y , вызванную влиянием прочих неучтенных в модели факторов и ошибками спецификации.
При парной линейной регрессии R 2 yx =r 2 yx .
(см. рисунок). Требуется найти уравнение прямой
Чем меньше числа по абсолютной величине, тем лучше подобрана прямая (2). В качестве характеристики точности подбора прямой (2) можно принять сумму квадратов
Условия минимума S будут
 |
(6) |
 |
(7) |
Уравнения (6) и (7) можно записать в таком виде:
 |
(8) |
 |
(9) |
Из уравнений (8) и (9) легко найти a и b по опытным значениям x i и y i . Прямая (2), определяемая уравнениями (8) и (9), называется прямой, полученной по методу наименьших квадратов (этим названием подчеркивается то, что сумма квадратов S имеет минимум). Уравнения (8) и (9), из которых определяется прямая (2), называются нормальными уравнениями.
Можно указать простой и общий способ составления нормальных уравнений. Используя опытные точки (1) и уравнение (2), можно записать систему уравнений для a и b
| y 1 =ax 1 +b, | |||
| y 2 =ax 2 +b, ... |
(10) | ||
| y n =ax n +b, | |||
Умножим левую и правую части каждого из этих уравнений на коэффициент при первой неизвестной a (т.е. на x 1 , x 2 , ..., x n) и сложим полученные уравнения, в результате получится первое нормальное уравнение (8).
Умножим левую и правую части каждого из этих уравнений на коэффициент при второй неизвестной b, т.е. на 1, и сложим полученные уравнения, в результате получится второе нормальное уравнение (9).
Этот способ получения нормальных уравнений является общим: он пригоден, например, и для функции
есть величина постоянная и ее нужно определить по опытным данным (1).
Систему уравнений для k можно записать:
Найти прямую (2) по методу наименьших квадратов.
Решение. Находим:
x i =21, y i =46,3, x i 2 =91, x i y i =179,1.
Записываем уравнения (8) и (9)
Отсюда находим
Оценка точности метода наименьших квадратов
Дадим оценку точности метода для линейного случая, когда имеет место уравнение (2).
Пусть опытные значения x i являются точными, а опытные значения y i имеют случайные ошибки с одинаковой дисперсией для всех i.
Введем обозначение
| (16) |
Тогда решения уравнений (8) и (9) можно представить в виде
| (17) | |
| (18) | |
| где | |
| (19) | |
| Из уравнения (17) находим | |
| (20) | |
| Аналогично из уравнения (18) получаем | |
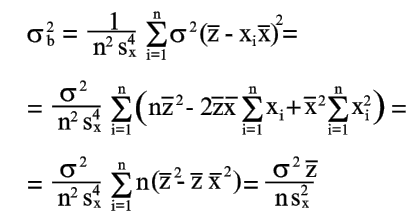 |
(21) |
| так как | |
| (22) | |
| Из уравнений (21) и (22) находим | |
 |
(23) |
Уравнения (20) и (23) дают оценку точности коэффициентов, определенных по уравнениям (8) и (9).
Заметим, что коэффициенты a и b коррелированы. Путем простых преобразований находим их корреляционный момент.
Отсюда находим
0,072 при x=1 и 6,
0,041 при x=3,5.
Литература
Шор. Я. Б. Статистические методы анализа и контроля качества и надежности. М.:Госэнергоиздат, 1962, с. 552, С. 92-98.
Настоящая книга предназначается для широкого круга инженеров (научно-исследовательских институтов, конструкторских бюро, полигонов и заводов), занимающихся определением качества и надежности радиоэлектронной аппаратуры и других массовых изделий промышленности (машиностроения, приборостроения, артиллерийской и т.п.).
В книге дается приложение методов математической статистики к вопросам обработки и оценки результатов испытаний, при которых определяются качество и надежность испытываемых изделий. Для удобства читателей приводятся необходимые сведения из математической статистики, а также большое число вспомогательных математических таблиц, облегчающих проведение необходимых расчетов.
Изложение иллюстрируется большим числом примеров, взятых из области радиоэлектроники и артиллерийской техники.
КУРСОВАЯ РАБОТА
по дисциплине: Информатика
Тема: Аппроксимация функции методом
наименьших квадратов
Введение
1. Постановка задачи
2. Расчётные формулы
Расчёт с помощью таблиц, выполненных средствами Microsoft Excel
Схема алгоритма
Расчет в программе MathCad
Результаты, полученные с помощью функции Линейн
Представление результатов в виде графиков
Введение
Целью курсовой работы является углубление знаний по информатике, развитие и закрепление навыков работы с табличным процессором Microsoft Excel и программным продуктом MathCAD и применение их для решения задач с помощью ЭВМ из предметной области, связанной с исследованиями.
Аппроксимация (от латинского "approximare" -"приближаться") - приближенное выражение каких-либо математических объектов (например, чисел или функций) через другие более простые, более удобные в пользовании или просто более известные. В научных исследованиях аппроксимация применяется для описания, анализа, обобщения и дальнейшего использования эмпирических результатов.
Как известно, между величинами может существовать точная (функциональная) связь, когда одному значению аргумента соответствует одно определенное значение, и менее точная (корреляционная) связь, когда одному конкретному значению аргумента соответствует приближенное значение или некоторое множество значений функции, в той или иной степени близких друг к другу. При ведении научных исследований, обработке результатов наблюдения или эксперимента обычно приходиться сталкиваться со вторым вариантом.
При изучении количественных зависимостей различных показателей, значения которых определяются эмпирически, как правило, имеется некоторая их вариабельность. Частично она задается неоднородностью самих изучаемых объектов неживой и, особенно, живой природы, частично - обуславливается погрешностью наблюдения и количественной обработке материалов. Последнюю составляющую не всегда удается исключить полностью, можно лишь минимизировать ее тщательным выбором адекватного метода исследования и аккуратностью работы. Поэтому при выполнении любой научно-исследовательской работы возникает проблема выявления подлинного характера зависимости изучаемых показателей, этой или иной степени замаскированных неучтенностью вариабельности: значений. Для этого и применяется аппроксимация - приближенное описание корреляционной зависимости переменных подходящим уравнением функциональной зависимости, передающим основную тенденцию зависимости (или ее "тренд").
При выборе аппроксимации следует исходить из конкретной задачи исследования. Обычно, чем более простое уравнение используется для аппроксимации, тем более приблизительно получаемое описание зависимости. Поэтому важно считывать, насколько существенны и чем обусловлены отклонения конкретных значений от получаемого тренда. При описании зависимости эмпирически определенных значений можно добиться и гораздо большей точности, используя какое-либо более сложное, много параметрическое уравнение. Однако нет никакого смысла стремиться с максимальной точностью передать случайные отклонения величин в конкретных рядах эмпирических данных. Гораздо важнее уловить общую закономерность, которая в данном случае наиболее логично и с приемлемой точностью выражается именно двухпараметрическим уравнением степенной функции. Таким образом, выбирая метод аппроксимации, исследователь всегда идет на компромисс: решает, в какой степени в данном случае целесообразно и уместно «пожертвовать» деталями и, соответственно, насколько обобщенно следует выразить зависимость сопоставляемых переменных. Наряду с выявлением закономерностей, замаскированных случайными отклонениями эмпирических данных от общей закономерности, аппроксимация позволяет также решать много других важных задач: формализовать найденную зависимость; найти неизвестные значения зависимой переменной путем интерполяции или, если это допустимо, экстраполяции.
В каждом задании формулируются условия задачи, исходные данные, форма
выдачи результатов, указываются основные математические зависимости для решения
задачи. В соответствии с методом решения задачи разрабатывается алгоритм
решения, который представляется в графической форме.
1. Постановка задачи
1. Используя метод наименьших квадратов функцию , заданную таблично, аппроксимировать:
а)
многочленом первой степени ![]() ;
;
б) многочленом второй степени ;
в) экспоненциальной зависимостью .
Для каждой зависимости вычислить коэффициент детерминированности.
Вычислить коэффициент корреляции (только в случае а).
Для каждой зависимости построить линию тренда.
Используя функцию ЛИНЕЙН вычислить числовые характеристики зависимости от .
Сравнить свои вычисления с результатами, полученными при помощи функции ЛИНЕЙН.
Сделать вывод, какая из полученных формул наилучшим образом аппроксимирует функцию .
Написать программу на одном из языков программирования и сравнить результаты счета с полученными выше.
Вариант
3. Функция задана табл. 1.
Таблица
1.
2. Расчётные формулы
Часто при анализе эмпирических данных возникает необходимость найти
функциональную зависимость между величинами x и y, которые получены в
результате опыта или измерений. Хi (независимая величина) задается экспериментатором, а yi , называемая
эмпирическими или опытными значениями получается в результате опыта. Аналитический вид функциональной зависимости, существующей между
величинами x и y обычно неизвестен, поэтому возникает практически важная задача
- найти эмпирическую формулу
(где
- параметры), значения которой при возможно мало отличались бы от опытных значений. Согласно
методу наименьших квадратов наилучшими коэффициентами считаются те, для которых сумма квадратов отклонений
найденной эмпирической функции от заданных значений функции будет минимальной.
Используя
необходимое условие экстремума функции нескольких переменных - равенство нулю
частных производных, находят набор коэффициентов , которые
доставляют минимум функции, определяемой формулой (2) и получают нормальную
систему для определения коэффициентов Таким
образом, нахождение коэффициентов сводится
к решению системы (3). Вид
системы (3) зависит от того, из какого класса эмпирических формул мы ищем
зависимость (1). В случае линейной зависимости система (3) примет вид:
В
случае квадратичной зависимости система
(3) примет вид:
В
ряде случаев в качестве эмпирической формулы берут функцию в которую
неопределенные коэффициенты входят нелинейно. При этом иногда задачу удается
линеаризовать т.е. свести к линейной. К числу таких зависимостей относится
экспоненциальная зависимость
где
a1и a2 неопределенные коэффициенты. Линеаризация
достигается путем логарифмирования равенства (6), после чего получаем
соотношение
Обозначим
и соответственно
через и , тогда
зависимость (6) может быть записана в виде , что
позволяет применить формулы (4) с заменой a1 на и на . График
восстановленной функциональной зависимости y(x) по результатам измерений (xi,
yi), i=1,2,…,n называется кривой регрессии. Для проверки согласия построенной
кривой регрессии с результатами эксперимента обычно вводят следующие числовые
характеристики: коэффициент корреляции (линейная зависимость), корреляционное
отношение и коэффициент детерминированности. Коэффициент
корреляции является мерой линейной связи между зависимыми случайными
величинами: он показывает, насколько хорошо в среднем может быть представлена
одна из величин в виде линейной функции от другой. Коэффициент
корреляции вычисляется по формуле:
где
- среднее арифметическое значение соответственно по
x, y. Коэффициент
корреляции между случайными величинами по абсолютной величине не превосходит 1.
Чем ближе к 1, тем теснее линейная связь между x и y. В случае нелинейной корреляционной связи условные средние значения
располагаются около кривой линии. В этом случае в качестве характеристики силы
связи рекомендуется использовать корреляционное отношение, интерпретация
которого не зависит от вида исследуемой зависимости. Корреляционное отношение вычисляется по формуле:
где
Всегда. Равенство = соответствует случайным некоррелированным величинам; = тогда и только тогда, когда имеется точная
функциональная связь между x и y. В случае линейной зависимости y от x
корреляционное отношение совпадает с квадратом коэффициента корреляции.
Величина используется в качестве индикатора отклонения
регрессии от линейной. Корреляционное
отношение является мерой корреляционной связи y c x в какой угодно форме, но не
может дать представления о степени приближенности эмпирических данных к
специальной форме. Чтобы выяснить насколько точно построен5ная кривая отражает
эмпирические данные вводится еще одна характеристика - коэффициент
детерминированности. Коэффициент
детерминированности определяется по формуле:
где
Sост = - остаточная сумма квадратов, характеризующая
отклонение экспериментальных данных от теоретических.полн - полная сумма квадратов, где среднее значение yi. Чем
меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем
больше значение коэффициента детерминированности r2, который показывает,
насколько хорошо уравнение, полученное с помощью регрессионного анализа,
объясняет взаимосвязи между переменными. Если он равен 1, то имеет место полная
корреляция с моделью, т.е. нет различия между фактическим и оценочным
значениями y. В противоположном случае, если коэффициент детерминированности
равен 0, то уравнение регрессии неудачно для предсказания значений y. Коэффициент
детерминированности всегда не превосходит корреляционное отношение. В случае
когда выполняется равенство то можно
считать, что построенная эмпирическая формула наиболее точно отражает
эмпирические данные.
3. Расчёт с помощью таблиц, выполненных средствами Microsoft Excel
Для проведения расчётов данные целесообразно расположить в виде таблицы
2, используя средства табличного процессора Microsoft Excel.
Таблица 2
Поясним, как таблица 2 составляется. Шаг 1.В ячейки А1:A25 заносим значения xi. Шаг 2.В ячейки B1:B25 заносим значения уi. Шаг 3.В ячейку С1 вводим формулу=А1^2. Шаг 4.В ячейки С1:С25 эта формула копируется. Шаг 5.В ячейку D1 вводим формулу=А1*B1. Шаг 6.В ячейки D1:D25 эта формула копируется. Шаг 7.В ячейку F1 вводим формулу=А1^4. Шаг 8.В ячейки F1:F25 эта формула копируется. Шаг 9.В ячейку G1 вводим формулу=А1^2*B1. Шаг 10.В ячейки G1:G25 эта формула копируется. Шаг 11.В ячейку H1 вводим формулу = LN(B1). Шаг 12.В ячейки H1:H25 эта формула копируется. Шаг 13.В ячейку I1 вводим формулу=А1*LN(B1). Шаг 14.В ячейки I1:I25 эта формула копируется. Последующие шаги делаем с помощью автосуммирования S. Шаг 15. В ячейку А26 вводим формулу = СУММ(А1:А25). Шаг 16. В ячейку В26 вводим формулу = СУММ(В1:В25). Шаг 17. В ячейку С26 вводим формулу = СУММ(С1:С25). Шаг 18. В ячейку D26 вводим формулу = СУММ(D1:D25). Шаг 19. В ячейку E26 вводим формулу = СУММ(E1:E25). Шаг 20. В ячейку F26 вводим формулу = СУММ(F1:F25). Шаг 21. В ячейку G26 вводим формулу = СУММ(G1:G25). Шаг 22. В ячейку H26 вводим формулу = СУММ(H1:H25). Шаг 23. В ячейку I26 вводим формулу = СУММ(I1:I25). Аппроксимируем
функцию линейной функцией . Для
определения коэффициентов и воспользуемся
системой (4). Используя итоговые суммы таблицы 2, расположенные в ячейках A26,
B26, C26 и D26, запишем систему (4) в виде решив
которую, получим Систему решали методом Крамера. Суть которого состоит в следующем.
Рассмотрим систему n алгебраических линейных уравнений с n неизвестными:
Определителем
системы называется определитель матрицы системы:
Обозначим
- определитель, который получится из определителя
системы Δ
заменой j-го столбца на столбец
Таким образом, линейная аппроксимация имеет вид
Решение
системы (11) проводим, пользуясь средствами Microsoft Excel. Результаты
представлены в таблице 3.
Таблица 3
Обратная матрица В таблице 3 в ячейках A32:B33 записана формула {=МОБР(А28:В29)}. В ячейках Е32:Е33 записана формула {=МУМНОЖ(А32:В33),(C28:С29)}. Далее
аппроксимируем функцию квадратичной функцией решив
которую, получим a1=10,663624, Таким
образом, квадратичная аппроксимация имеет вид
Решение
системы (16) проводим, пользуясь средствами Microsoft Excel. Результаты
представлены в таблице 4. Таблица
4
Обратная матрица В таблице 4 в ячейках А41:С43 записана формула {=МОБР(А36:С38)}. В ячейках F41:F43 записана формула {=МУМНОЖ(А41:C43),(D36:D38)}. Теперь
аппроксимируем функцию экспоненциальной функцией . Для определения коэффициентов и прологарифмируем
значения и, используя итоговые суммы таблицы 2, расположенные
в ячейках A26, C26, H26 и I26, получим систему
Решив
систему (18), получим и . После
потенцирования получим . Таким
образом, экспоненциальная аппроксимация имеет вид Решение
системы (18) проводим, пользуясь средствами Microsoft Excel. Результаты
представлены в таблице 5. Таблица
5
Обратная матрица В ячейках А50:В51 записана формула {=МОБР(А46:В47)}. В ячейках Е49:Е50 записана формула {=МУМНОЖ(А50:В51),(С46:С47)}. В ячейке Е51 записана формула=EXP(E49). Вычислим
среднее арифметическое и по
формулам:
Результаты
расчета и средствами
Microsoft Excel представлены в таблице 6.
Таблица 6
В ячейке В54 записана формула=А26/25. В ячейке В55 записана формула=В26/25 Таблица 7
Шаг 1.В ячейку J1 вводим формулу = (А1-$B$54)*(B1-$B$55). Шаг 2.В ячейки J2:J25 эта формула копируется. Шаг 3.В ячейку K1 вводим формулу = (А1-$B$54)^2. Шаг 4.В ячейки k2:K25 эта формула копируется. Шаг 5.В ячейку L1 вводим формулу = (B1-$B$55)^2. Шаг 6.В ячейки L2:L25 эта формула копируется. Шаг 7.В ячейку M1 вводим формулу = ($E$32+$E$33*A1-B1)^2. Шаг 8.В ячейки M2:M25 эта формула копируется. Шаг 9.В ячейку N1 вводим формулу = ($F$41+$F$42*A1+$F$43*A1^2-B1)^2. Шаг 10.В ячейки N2:N25 эта формула копируется. Шаг 11.В ячейку O1 вводим формулу = ($E$51*EXP($E$50*A1)-B1)^2. Шаг 12.В ячейки O2:O25 эта формула копируется. Последующие шаги делаем с помощью авто суммирования S. Шаг 13.В ячейку J26 вводим формулу = CУММ(J1:J25). Шаг 14.В ячейку K26 вводим формулу = CУММ(K1:K25). Шаг 15.В ячейку L26 вводим формулу = CУММ(L1:L25). Шаг 16.В ячейку M26 вводим формулу = CУММ(M1:M25). Шаг 17.В ячейку N26 вводим формулу = CУММ(N1:N25). Шаг 18.В ячейку O26 вводим формулу = CУММ(O1:O25). Теперь проведем расчеты коэффициента корреляции по формуле (8) (только
для линейной аппроксимации) и коэффициента детерминированности по формуле (10).
Результаты расчетов средствами Microsoft Excel представлены в таблице 8.
Таблица 8
Коэффициент корреляции Коэффициент
детерминированности (линейная аппроксимация) Коэффициент
детерминированности (квадратичная аппроксимация) Коэффициент
детерминированности (экспоненциальная аппроксимация) В ячейке E57 записана формула=J26/(K26*L26)^(1/2). В ячейке E59 записана формула=1-M26/L26. В ячейке E61 записана формула=1-N26/L26. В ячейке E63 записана формула=1-O26/L26. Анализ результатов расчетов показывает, что квадратичная аппроксимация
наилучшим образом описывает экспериментальные данные.
Схема алгоритма
Рис. 1. Схема алгоритма для программы расчёта. 5. Расчет в программе MathCad
Линейная регрессия · line (x, y) - вектор из двух элементов (b, a) коэффициентов
линейной регрессии b+ax; · x - вектор действительных данных аргумента; · y - вектор действительных данных значений того же размера.
Рисунок 2.
Полиномиальная
регрессия означает приближение данных (х1, у1) полиномом k-й степени При k=i полином является прямой линией, при k=2 -
параболой, при k=3 - кубической параболой и т.д. Как правило, на практике
применяются k<5. · regress (x,y,k) - вектор коэффициентов для построения
полиномиальной регрессии данных; · interp (s,x,y,t) - результат полиномиальной регрессии; · s=regress(x,y,k); · x - вектор действительных данных аргумента, элементы которого
расположены в порядке возрастания; · y - вектор действительных данных значений того же размера; · k - степень полинома регрессии (целое положительное число); · t - значение аргумента полинома регрессии.
Рисунок 3
Кроме рассмотренных, в Mathcad встроено еще несколько видов
трехпараметрической регрессии, их реализация несколько отличается от
приведенных выше вариантов регрессии тем, что для них, помимо массива данных,
требуется задать некоторые начальные значения коэффициентов a, b, c.
Используйте соответствующий вид регрессии, если хорошо представляете себе,
какой зависимостью описывается ваш массив данных. Когда тип регрессии плохо
отражает последовательность данных, то ее результат часто бывает
неудовлетворительным и даже сильно различающимся в зависимости от выбора
начальных значений. Каждая из функций выдает вектор уточненных параметров a, b,
c.
Результаты, полученные с помощью функции ЛИНЕЙН
Рассмотрим назначение функции ЛИНЕЙН. Эта функция использует метод наименьших квадратов, чтобы вычислить прямую
линию, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает полученную прямую. Уравнение
для прямой линии имеет следующий вид: M1x1 + m2x2 + ... + b или y = mx + b, алгоритм табличный microsoft программный где зависимое значение y является функцией независимого значения x.
Значения m - это коэффициенты, соответствующие каждой независимой переменной x,
а b - это постоянная. Заметим, что y, x и m могут быть векторами. Для получения результатов необходимо создать табличную формулу, которая
будет занимать 5 строк и 2 столбца. Этот интервал может располагаться в
произвольном месте на рабочем листе. В этот интервал требуется ввести функцию
ЛИНЕЙН. В результате должны заполниться все ячейки интервала А65:В69 (как
показано в таблице 9).
Таблица 9.
Поясним назначение некоторых величин, расположенных в таблице 9. Величины, расположенные в ячейках А65 и В65 характеризуют соответственно
наклон и сдвиг.- коэффициент детерминированности.- F-наблюдаемое значение.-
число степеней свободы.- регрессионная сумма квадратов.- остаточная сумма
квадратов.
Представление результатов в виде графиков
Рис. 4. График линейной аппроксимации
Рис. 5. График квадратичной аппроксимации
Рис. 6. График экспоненциальной аппроксимации
Выводы
Сделаем выводы по результатам полученных данных. Анализ результатов расчетов показывает, что квадратичная аппроксимация
наилучшим образом описывает экспериментальные данные, т.к. линия тренда для неё
наиболее точно отражает поведение функции на данном участке. Сравнивая результаты, полученные при помощи функции ЛИНЕЙН, видим, что
они полностью совпадают с вычислениями, проведенными выше. Это указывает на то,
что вычисления верны. Результаты, полученные с помощью программы MathCad, полностью совпадают
со значениями приведенными выше. Это говорит о верности вычислений.
Список используемой литературы
1
Б.П. Демидович,
И.А. Марон. Основы вычислительной математики. М: Государственное издательство
физико-математической литературы. 2
Информатика:
Учебник под ред. проф. Н.В. Макаровой. М: Финансы и статистика, 2007. 3
Информатика:
Практикум по технологии работы на компьютере под ред. проф. Н.В. Макаровой. М:
Финансы и статистика, 2010. 4
В.Б. Комягин.
Программирование в Excel на языке Visual Basic. М: Радио и связь, 2007. 5
Н. Николь, Р.
Альбрехт. Excel. Электронные таблицы. М: Изд. «ЭКОМ», 2008. 6
Методические
указания к выполнению курсовой работы по информатике (для студентов заочного
отделения всех специальностей), под ред. Журова Г. Н., СПбГГИ(ТУ), 2011.
![]() , (1)
, (1)
![]() :
:![]() (3)
(3)
 (4)
(4)
 (5)
(5)
![]() (7)
(7)
 (8)
(8) (9)
(9) (10)
(10)
![]() а числитель характеризует рассеяние условных средних
около безусловного среднего.
а числитель характеризует рассеяние условных средних
около безусловного среднего.![]() -
регрессионная сумма квадратов, характеризующая разброс данных.
-
регрессионная сумма квадратов, характеризующая разброс данных.
 (11)
(11)
![]() и .
и . (12)
(12)
 (13)
(13)
![]() .
Для определения коэффициентов a1, a2 и a3 воспользуемся системой (5). Используя
итоговые суммы таблицы 2, расположенные в ячейках A26, B26, C26 , D26, E26,
F26, G26 запишем систему (5) в виде
.
Для определения коэффициентов a1, a2 и a3 воспользуемся системой (5). Используя
итоговые суммы таблицы 2, расположенные в ячейках A26, B26, C26 , D26, E26,
F26, G26 запишем систему (5) в виде
 (16)
(16)
![]() и
и ![]()
 (18)
(18)








Приблизим функцию многочленом 2-ой степени. Для этого вычислим коэффициенты нормальной системы уравнений:
,  ,
, 
Составим нормальную систему наименьших квадратов, которая имеет вид:

Решение системы легко находится:, , .
Таким образом, многочлен 2-ой степени найден: .
Теоретическая справка
Вернуться на страницу <Введение в вычислительную математику. Примеры>
Пример 2 . Нахождение оптимальной степени многочлена.
Вернуться на страницу <Введение в вычислительную математику. Примеры>
Пример 3 . Вывод нормальной системы уравнений для нахождения параметров эмпирической зависимости.
Выведем систему уравнений для определения коэффициентов и функции ![]() , осуществляющей среднеквадратичную аппроксимацию заданной функции по точкам. Составим функцию
, осуществляющей среднеквадратичную аппроксимацию заданной функции по точкам. Составим функцию![]() и запишем для нее необходимое условие экстремума:
и запишем для нее необходимое условие экстремума:

Тогда нормальная система примет вид:

Получили линейную систему уравнений относительно неизвестных параметров и, которая легко решается.
Теоретическая справка
Вернуться на страницу <Введение в вычислительную математику. Примеры>
Пример.
Экспериментальные данные о значениях переменных х
и у
приведены в таблице.
В результате их выравнивания получена функция ![]()
Используя метод наименьших квадратов , аппроксимировать эти данные линейной зависимостью y=ax+b (найти параметры а и b ). Выяснить, какая из двух линий лучше (в смысле метода наименьших квадратов) выравнивает экспериментальные данные. Сделать чертеж.
Суть метода наименьших квадратов (МНК).
Задача заключается в нахождении коэффициентов линейной зависимости, при которых функция двух переменных а
и b
![]() принимает наименьшее значение. То есть, при данных а
и b
сумма квадратов отклонений экспериментальных данных от найденной прямой будет наименьшей. В этом вся суть метода наименьших квадратов.
принимает наименьшее значение. То есть, при данных а
и b
сумма квадратов отклонений экспериментальных данных от найденной прямой будет наименьшей. В этом вся суть метода наименьших квадратов.
Таким образом, решение примера сводится к нахождению экстремума функции двух переменных.
Вывод формул для нахождения коэффициентов.
Составляется и решается система из двух уравнений с двумя неизвестными. Находим частные производные функции ![]() по переменным а
и b
, приравниваем эти производные к нулю.
по переменным а
и b
, приравниваем эти производные к нулю.
Решаем полученную систему уравнений любым методом (например методом подстановки
или методом Крамера) и получаем формулы для нахождения коэффициентов по методу наименьших квадратов (МНК).
При данных а
и b
функция ![]() принимает наименьшее значение. Доказательство этого факта приведено ниже по тексту в конце страницы.
принимает наименьшее значение. Доказательство этого факта приведено ниже по тексту в конце страницы.
Вот и весь метод наименьших квадратов. Формула для нахождения параметра a содержит суммы , , , и параметр n — количество экспериментальных данных. Значения этих сумм рекомендуем вычислять отдельно.
Коэффициент b находится после вычисления a .
Пришло время вспомнить про исходый пример.
Решение.
В нашем примере n=5
. Заполняем таблицу для удобства вычисления сумм, которые входят в формулы искомых коэффициентов.
Значения в четвертой строке таблицы получены умножением значений 2-ой строки на значения 3-ей строки для каждого номера i .
Значения в пятой строке таблицы получены возведением в квадрат значений 2-ой строки для каждого номера i .
Значения последнего столбца таблицы – это суммы значений по строкам.
Используем формулы метода наименьших квадратов для нахождения коэффициентов а
и b
. Подставляем в них соответствующие значения из последнего столбца таблицы:
Следовательно, y = 0.165x+2.184 — искомая аппроксимирующая прямая.
Осталось выяснить какая из линий y = 0.165x+2.184
или ![]() лучше аппроксимирует исходные данные, то есть произвести оценку методом наименьших квадратов.
лучше аппроксимирует исходные данные, то есть произвести оценку методом наименьших квадратов.
Оценка погрешности метода наименьших квадратов.
Для этого требуется вычислить суммы квадратов отклонений исходных данных от этих линий ![]() и
и ![]() , меньшее значение соответствует линии, которая лучше в смысле метода наименьших квадратов аппроксимирует исходные данные.
, меньшее значение соответствует линии, которая лучше в смысле метода наименьших квадратов аппроксимирует исходные данные.
Так как , то прямая y = 0.165x+2.184 лучше приближает исходные данные.
Графическая иллюстрация метода наименьших квадратов (мнк).
На графиках все прекрасно видно. Красная линия – это найденная прямая y = 0.165x+2.184
, синяя линия – это ![]() , розовые точки – это исходные данные.
, розовые точки – это исходные данные.

Для чего это нужно, к чему все эти аппроксимации?
Я лично использую для решения задач сглаживания данных, задач интерполяции и экстраполяции (в исходном примере могли бы попросить найти занчение наблюдаемой величины y при x=3 или при x=6 по методу МНК). Но подробнее поговорим об этом позже в другом разделе сайта.
К началу страницы
Доказательство.
Чтобы при найденных а
и b
функция принимала наименьшее значение, необходимо чтобы в этой точке матрица квадратичной формы дифференциала второго порядка для функции ![]() была положительно определенной. Покажем это.
была положительно определенной. Покажем это.
Дифференциал второго порядка имеет вид:
То есть
Следовательно, матрица квадратичной формы имеет вид
причем значения элементов не зависят от а
и b
.
Покажем, что матрица положительно определенная. Для этого нужно, чтобы угловые миноры были положительными.
Угловой минор первого порядка  . Неравенство строгое, так как точки несовпадающие. В дальнейшем это будем подразумевать.
. Неравенство строгое, так как точки несовпадающие. В дальнейшем это будем подразумевать.
Угловой минор второго порядка
Докажем, что  методом математической индукции.
методом математической индукции.

Вывод
: найденные значения а
и b
соответствуют наименьшему значению функции ![]() , следовательно, являются искомыми параметрами для метода наименьших квадратов.
, следовательно, являются искомыми параметрами для метода наименьших квадратов.
Некогда разбираться?
Закажите решение
К началу страницы
Разработка прогноза с помощью метода наименьших квадратов. Пример решения задачи
Экстраполяция — это метод научного исследования, который основан на распространении прошлых и настоящих тенденций, закономерностей, связей на будущее развитие объекта прогнозирования. К методам экстраполяции относятся метод скользящей средней, метод экспоненциального сглаживания, метод наименьших квадратов.
Сущность метода наименьших квадратов состоит в минимизации суммы квадратических отклонений между наблюдаемыми и расчетными величинами. Расчетные величины находятся по подобранному уравнению – уравнению регрессии. Чем меньше расстояние между фактическими значениями и расчетными, тем более точен прогноз, построенный на основе уравнения регрессии.
Теоретический анализ сущности изучаемого явления, изменение которого отображается временным рядом, служит основой для выбора кривой. Иногда принимаются во внимание соображения о характере роста уровней ряда. Так, если рост выпуска продукции ожидается в арифметической прогрессии, то сглаживание производится по прямой. Если же оказывается, что рост идет в геометрической прогрессии, то сглаживание надо производить по показательной функции.
Рабочая формула метода наименьших квадратов : У t+1 = а*Х + b , где t + 1 – прогнозный период; Уt+1 – прогнозируемый показатель; a и b — коэффициенты; Х — условное обозначение времени.
Расчет коэффициентов a и b осуществляется по следующим формулам:
 |
 |
где, Уф – фактические значения ряда динамики; n – число уровней временного ряда;
Сглаживание временных рядов методом наименьших квадратов служит для отражения закономерности развития изучаемого явления. В аналитическом выражении тренда время рассматривается как независимая переменная, а уровни ряда выступают как функция этой независимой переменной.
Развитие явления зависит не от того, сколько лет прошло с отправного момента, а от того, какие факторы влияли на его развитие, в каком направлении и с какой интенсивностью. Отсюда ясно, что развитие явления во времени выступает как результат действия этих факторов.
Правильно установить тип кривой, тип аналитической зависимости от времени – одна из самых сложных задач предпрогнозного анализа .
Подбор вида функции, описывающей тренд, параметры которой определяются методом наименьших квадратов, производится в большинстве случаев эмпирически, путем построения ряда функций и сравнения их между собой по величине среднеквадратической ошибки, вычисляемой по формуле:
 |
где Уф – фактические значения ряда динамики; Ур – расчетные (сглаженные) значения ряда динамики; n – число уровней временного ряда; р – число параметров, определяемых в формулах, описывающих тренд (тенденцию развития).
Недостатки метода наименьших квадратов :
- при попытке описать изучаемое экономическое явление с помощью математического уравнения, прогноз будет точен для небольшого периода времени и уравнение регрессии следует пересчитывать по мере поступления новой информации;
- сложность подбора уравнения регрессии, которая разрешима при использовании типовых компьютерных программ.
Пример применения метода наименьших квадратов для разработки прогноза
Задача . Имеются данные, характеризующие уровень безработицы в регионе, %
- Постройте прогноз уровня безработицы в регионе на ноябрь, декабрь, январь месяцы, используя методы: скользящей средней, экспоненциального сглаживания, наименьших квадратов.
- Рассчитайте ошибки полученных прогнозов при использовании каждого метода.
- Сравните полученные результаты, сделайте выводы.
Решение методом наименьших квадратов
Для решения составим таблицу, в которой будем производить необходимые расчеты:
ε = 28,63/10 = 2,86% точность прогноза высокая.
Вывод : Сравнивая результаты, полученные при расчетах методом скользящей средней , методом экспоненциального сглаживания и методом наименьших квадратов, можно сказать, что средняя относительная ошибка при расчетах методом экспоненциального сглаживания попадает в пределы 20-50%. Это значит, что точность прогноза в данном случае является лишь удовлетворительной.
В первом и третьем случае точность прогноза является высокой, поскольку средняя относительная ошибка менее 10%. Но метод скользящих средних позволил получить более достоверные результаты (прогноз на ноябрь – 1,52%, прогноз на декабрь – 1,53%, прогноз на январь – 1,49%), так как средняя относительная ошибка при использовании этого метода наименьшая – 1,13%.
Метод наименьших квадратов
Другие статьи по данной теме:
Список использованных источников
- Научно-методические рекомендации по вопросам диагностики социальных рисков и прогнозирования вызовов, угроз и социальных последствий. Российский государственный социальный университет. Москва. 2010;
- Владимирова Л.П. Прогнозирование и планирование в условиях рынка: Учеб. пособие. М.: Издательский Дом «Дашков и Ко», 2001;
- Новикова Н.В., Поздеева О.Г. Прогнозирование национальной экономики: Учебно-методическое пособие. Екатеринбург: Изд-во Урал. гос. экон. ун-та, 2007;
- Слуцкин Л.Н. Курс МБА по прогнозированию в бизнесе. М.: Альпина Бизнес Букс, 2006.
Программа МНК
Введите данные
Данные и аппроксимация y = a + b·x
i
- номер экспериментальной точки;
x i
- значение фиксированного параметра в точке i
;
y i
- значение измеряемого параметра в точке i
;
ω i
- вес измерения в точке i
;
y i, расч.
- разница между измеренным и вычисленным по регрессии значением y
в точке i
;
S x i (x i)
- оценка погрешности x i
при измерении y
в точке i
.
Данные и аппроксимация y = k·x
| i | x i | y i | ω i | y i, расч. | Δy i | S x i (x i) |
|---|
Кликните по графику,
Инструкция пользователя онлайн-программы МНК.
В поле данных введите на каждой отдельной строке значения `x` и `y` в одной экспериментальной точке. Значения должны отделяться пробельным символом (пробелом или знаком табуляции).
Третьим значением может быть вес точки `w`. Если вес точки не указан, то он приравнивается единице. В подавляющем большинстве случаев веса экспериментальных точек неизвестны или не вычисляются, т.е. все экспериментальные данные считаются равнозначными. Иногда веса в исследуемом интервале значений совершенно точно не равнозначны и даже могут быть вычислены теоретически. Например, в спектрофотометрии веса можно вычислить по простым формулам, правда в основном этим все пренебрегают для уменьшения трудозатрат.
Данные можно вставить через буфер обмена из электронной таблицы офисных пакетов, например Excel из Майкрософт Офиса или Calc из Оупен Офиса. Для этого в электронной таблице выделите диапазон копируемых данных, скопируйте в буфер обмена и вставьте данные в поле данных на этой странице.
Для расчета по методу наименьших квадратов необходимо не менее двух точек для определения двух коэффициентов `b` - тангенса угла наклона прямой и `a` - значения, отсекаемого прямой на оси `y`.
Для оценки погрешности расчитываемых коэффициентов регресии нужно задать количество экспериментальных точек больше двух.
Метод наименьших квадратов (МНК).
Чем больше количество экспериментальных точек, тем более точна статистическая оценка коэффицинетов (за счет снижения коэффицинета Стьюдента) и тем более близка оценка к оценке генеральной выборки.
Получение значений в каждой экспериментальной точке часто сопряжено со значительными трудозатратами, поэтому часто проводят компромиссное число экспериментов, которые дает удобоваримую оценку и не привеодит к чрезмерным трудо затратам. Как правило число экспериментах точек для линейной МНК зависимости с двумя коэффицинетами выбирает в районе 5-7 точек.
Краткая теория метода наименьших квадратов для линейной зависимости
Допустим у нас имеется набор экспериментальных данных в виде пар значений [`y_i`, `x_i`], где `i` - номер одного эксперементального измерения от 1 до `n`; `y_i` - значение измеренной величины в точке `i`; `x_i` - значение задаваемого нами параметра в точке `i`.
В качестве примера можно рассмотреть действие закона Ома. Изменяя напряжение (разность потенциалов) между участками электрической цепи, мы замеряем величину тока, проходящего по этому участку. Физика нам дает зависимость, найденную экспериментально:
`I = U / R`,
где `I` - сила тока; `R` - сопротивление; `U` - напряжение.
В этом случае `y_i` у нас имеряемая величина тока, а `x_i` - значение напряжения.
В качестве другого примера рассмотрим поглощение света раствором вещества в растворе. Химия дает нам формулу:
`A = ε l C`,
где `A` - оптическая плотность раствора; `ε` - коэффициент пропускания растворенного вещества; `l` - длина пути при прохождении света через кювету с раствором; `C` - концентрация растворенного вещества.
В этом случае `y_i` у нас имеряемая величина отптической плотности `A`, а `x_i` - значение концентрации вещества, которое мы задаем.
Мы будем рассматривать случай, когда относительная погрешность в задании `x_i` значительно меньше, относительной погрешности измерения `y_i`. Так же мы будем предполагать, что все измеренные величины `y_i` случайные и нормально распределенные, т.е. подчиняются нормальному закону распределения.
В случае линейной зависимости `y` от `x`, мы можем написать теоретическую зависимость:
`y = a + b x`.
С геометрической точки зрения, коэффициент `b` обозначает тангенс угла наклона линии к оси `x`, а коэффициент `a` - значение `y` в точке пересечения линии с осью `y` (при `x = 0`).
Нахождение параметров линии регресии.
В эксперименте измеренные значения `y_i` не могут точно лечь на теоеретическую прямую из-за ошибок измерения, всегда присущих реальной жизни. Поэтому линейное уравнение, нужно представить системой уравнений:
`y_i = a + b x_i + ε_i` (1),
где `ε_i` - неизвестная ошибка измерения `y` в `i`-ом эксперименте.
Зависимость (1) так же называют регрессией , т.е. зависимостью двух величин друг от друга со статистической значимостью.
Задачей восстановления зависимости является нахождение коэффициентов `a` и `b` по экспериментальным точкам [`y_i`, `x_i`].
Для нахождения коэффициентов `a` и `b` обычно используется метод наименьших квадратов (МНК). Он является частным случаем принципа максимального правдоподобия.
Перепишем (1) в виде `ε_i = y_i — a — b x_i`.
Тогда сумма квадратов ошибок будет
`Φ = sum_(i=1)^(n) ε_i^2 = sum_(i=1)^(n) (y_i — a — b x_i)^2`. (2)
Принципом МНК (метода наименьших квадратов) является минимизация суммы (2) относительно параметров `a` и `b` .
Минимум достигается, когда частные производные от суммы (2) по коэффициентам `a` и `b` равны нулю:
`frac(partial Φ)(partial a) = frac(partial sum_(i=1)^(n) (y_i — a — b x_i)^2)(partial a) = 0`
`frac(partial Φ)(partial b) = frac(partial sum_(i=1)^(n) (y_i — a — b x_i)^2)(partial b) = 0`
Раскрывая производные, получаем систему из двух уравнений с двумя неизвестными:
`sum_(i=1)^(n) (2a + 2bx_i — 2y_i) = sum_(i=1)^(n) (a + bx_i — y_i) = 0`
`sum_(i=1)^(n) (2bx_i^2 + 2ax_i — 2x_iy_i) = sum_(i=1)^(n) (bx_i^2 + ax_i — x_iy_i) = 0`
Раскрываем скобки и переносим независящие от искомых коэффициентов суммы в другую половину, получим систему линейных уравнений:
`sum_(i=1)^(n) y_i = a n + b sum_(i=1)^(n) bx_i`
`sum_(i=1)^(n) x_iy_i = a sum_(i=1)^(n) x_i + b sum_(i=1)^(n) x_i^2`
Решая, полученную систему, находим формулы для коэффициентов `a` и `b`:
`a = frac(sum_(i=1)^(n) y_i sum_(i=1)^(n) x_i^2 — sum_(i=1)^(n) x_i sum_(i=1)^(n) x_iy_i) (n sum_(i=1)^(n) x_i^2 — (sum_(i=1)^(n) x_i)^2)` (3.1)
`b = frac(n sum_(i=1)^(n) x_iy_i — sum_(i=1)^(n) x_i sum_(i=1)^(n) y_i) (n sum_(i=1)^(n) x_i^2 — (sum_(i=1)^(n) x_i)^2)` (3.2)
Эти формулы имеют решения, когда `n > 1` (линию можно построить не менее чем по 2-м точкам) и когда детерминант `D = n sum_(i=1)^(n) x_i^2 — (sum_(i=1)^(n) x_i)^2 != 0`, т.е. когда точки `x_i` в эксперименте различаются (т.е. когда линия не вертикальна).
Оценка погрешностей коэффициентов линии регресии
Для более точной оценки погрешности вычисления коэффициентов `a` и `b` желательно большое количество экспериментальных точек. При `n = 2`, оценить погрешность коэффициентов невозможно, т.к. аппроксимирующая линия будет однозначно проходить через две точки.
Погрешность случайной величины `V` определяется законом накопления ошибок
`S_V^2 = sum_(i=1)^p (frac(partial f)(partial z_i))^2 S_(z_i)^2`,
где `p` - число параметров `z_i` с погрешностью `S_(z_i)`, которые влияют на погрешность `S_V`;
`f` - функция зависимости `V` от `z_i`.
Распишем закон накопления ошибок для погрешности коэффициентов `a` и `b`
`S_a^2 = sum_(i=1)^(n)(frac(partial a)(partial y_i))^2 S_(y_i)^2 + sum_(i=1)^(n)(frac(partial a)(partial x_i))^2 S_(x_i)^2 = S_y^2 sum_(i=1)^(n)(frac(partial a)(partial y_i))^2 `,
`S_b^2 = sum_(i=1)^(n)(frac(partial b)(partial y_i))^2 S_(y_i)^2 + sum_(i=1)^(n)(frac(partial b)(partial x_i))^2 S_(x_i)^2 = S_y^2 sum_(i=1)^(n)(frac(partial b)(partial y_i))^2 `,
т.к. `S_(x_i)^2 = 0` (мы ранее сделали оговорку, что погрешность `x` пренебрежительно мала).
`S_y^2 = S_(y_i)^2` - погрешность (дисперсия, квадрат стандартного отклонения) в измерении `y` в предположении, что погрешность однородна для всех значений `y`.
Подставляя в полученные выражения формулы для расчета `a` и `b` получим
`S_a^2 = S_y^2 frac(sum_(i=1)^(n) (sum_(i=1)^(n) x_i^2 — x_i sum_(i=1)^(n) x_i)^2) (D^2) = S_y^2 frac((n sum_(i=1)^(n) x_i^2 — (sum_(i=1)^(n) x_i)^2) sum_(i=1)^(n) x_i^2) (D^2) = S_y^2 frac(sum_(i=1)^(n) x_i^2) (D)` (4.1)
`S_b^2 = S_y^2 frac(sum_(i=1)^(n) (n x_i — sum_(i=1)^(n) x_i)^2) (D^2) = S_y^2 frac(n (n sum_(i=1)^(n) x_i^2 — (sum_(i=1)^(n) x_i)^2)) (D^2) = S_y^2 frac(n) (D)` (4.2)
В большинстве реальных экспериментов значение `Sy` не измеряется. Для этого нужно проводить несколько паралельных измерений (опытов) в одной или нескольких точках плана, что увеличивает время (и возможно стоимость) эксперимента. Поэтому обычно полагают, что отклонение `y` от линии регрессии можно считать случайным. Оценку дисперсии `y` в этом случае, считают по формуле.
`S_y^2 = S_(y, ост)^2 = frac(sum_(i=1)^n (y_i — a — b x_i)^2) (n-2)`.
Делитель `n-2` появляется потому, что у нас снизилось число степеней свободы из-за расчета двух коэффициентов по этой же выборке экспериментальных данных.
Такую оценку еще называют остаточной дисперсией относительно линии регрессии `S_(y, ост)^2`.
Оценка значимости коэффициентов проводится по критерию Стьюдента
`t_a = frac(|a|) (S_a)`, `t_b = frac(|b|) (S_b)`
Если рассчитанные критерии `t_a`, `t_b` меньше табличных критериев `t(P, n-2)`, то считается, что соответсвующий коэффициент не значимо отличается от нуля с заданной вероятностью `P`.
Для оценки качества описания линейной зависимости, можно сравнить `S_(y, ост)^2` и `S_(bar y)` относительно среднего с использованием критерия Фишера.
`S_(bar y) = frac(sum_(i=1)^n (y_i — bar y)^2) (n-1) = frac(sum_(i=1)^n (y_i — (sum_(i=1)^n y_i) /n)^2) (n-1)` - выборочная оценка дисперсии `y` относительно среднего.
Для оценки эффективности уравнения регресии для описания зависимости расчитывают коэффициент Фишера
`F = S_(bar y) / S_(y, ост)^2`,
который сравнивают с табличным коэффициентом Фишера `F(p, n-1, n-2)`.
Если `F > F(P, n-1, n-2)`, считается статистически значимым с вероятностью `P` различие между описанием зависимости `y = f(x)` с помощью уравенения регресии и описанием с помощью среднего. Т.е. регрессия лучше описывает зависимость, чем разброс `y` относительно среднего.
Кликните по графику,
чтобы добавить значения в таблицу
Метод наименьших квадратов. Под методом наименьших квадратов понимается определение неизвестных параметров a, b, c, принятой функциональной зависимости
Под методом наименьших квадратов понимается определение неизвестных параметров a, b, c,… принятой функциональной зависимости
y = f(x,a,b,c,…) ,
которые обеспечивали бы минимум среднего квадрата (дисперсии) ошибки
 , (24)
, (24)
где x i , y i – совокупность пар чисел, полученных из эксперимента.
Так как условием экстремума функции нескольких переменных является условие равенства нулю ее частных производных, то параметры a, b, c,… определяются из системы уравнений:
; ; ; … (25)
Необходимо помнить, что метод наименьших квадратов применяется для подбора параметров после того, как вид функции y = f(x) определен.
Если из теоретических соображений нельзя сделать никаких выводов о том, какой должна быть эмпирическая формула, то приходится руководствоваться наглядными представлениями, прежде всего графическим изображением наблюденных данных.
На практике чаще всего ограничиваются следующими видами функций:
1) линейная ![]() ;
;
2) квадратичная a .